
I was inspired by to explore my own universe of augmented piano playing. Could I write a program that learns in realtime to improvise with my style in the music breaks between my own playing? 🤖🎹
This is pretty much a play-by-play on making PianoAI. If you just want to try out PianoAI, . Otherwise, stay here to read about my many programming follies.
Inspiration
After watching , I did some freeze frames of his computer and found out he uses the to connect up to his (very fancy) MIDI keyboard. I pretty easily managed to get together with my own (not fancy) MIDI keyboard.
As explained in the video, Dan's augmented piano playing basically allows you to mirror or echo certain notes in specified patterns. A lot of his patterns seem to be song dependent. After thinking, I decided I was interested in something a little different. I wanted to a piano accompaniment that learns in realtime to emulate my style and improvise in the spaces between my own playing, on any song.
I'm not the first to make a Piano AI. Google made the which is a great program. But I wanted to see if I could make an A.I. specifically tuned to my own style.
A journey into AI
My equipment is nothing special. I bought it used from some guy who decided he had to give up trying to learn how to play piano 😢. Pretty much any MIDI keyboard and MIDI adapter will do.
I generally need to do everything at least twice in order to get it right. Also I need to draw everything out clearly in order to actually understand what I'm doing. My process for writing programs then is basically as follows:
- Draw it out on paper.
- Program it in Python.
- Start over.
- Draw it out on paper, again.
- Program it in Go.
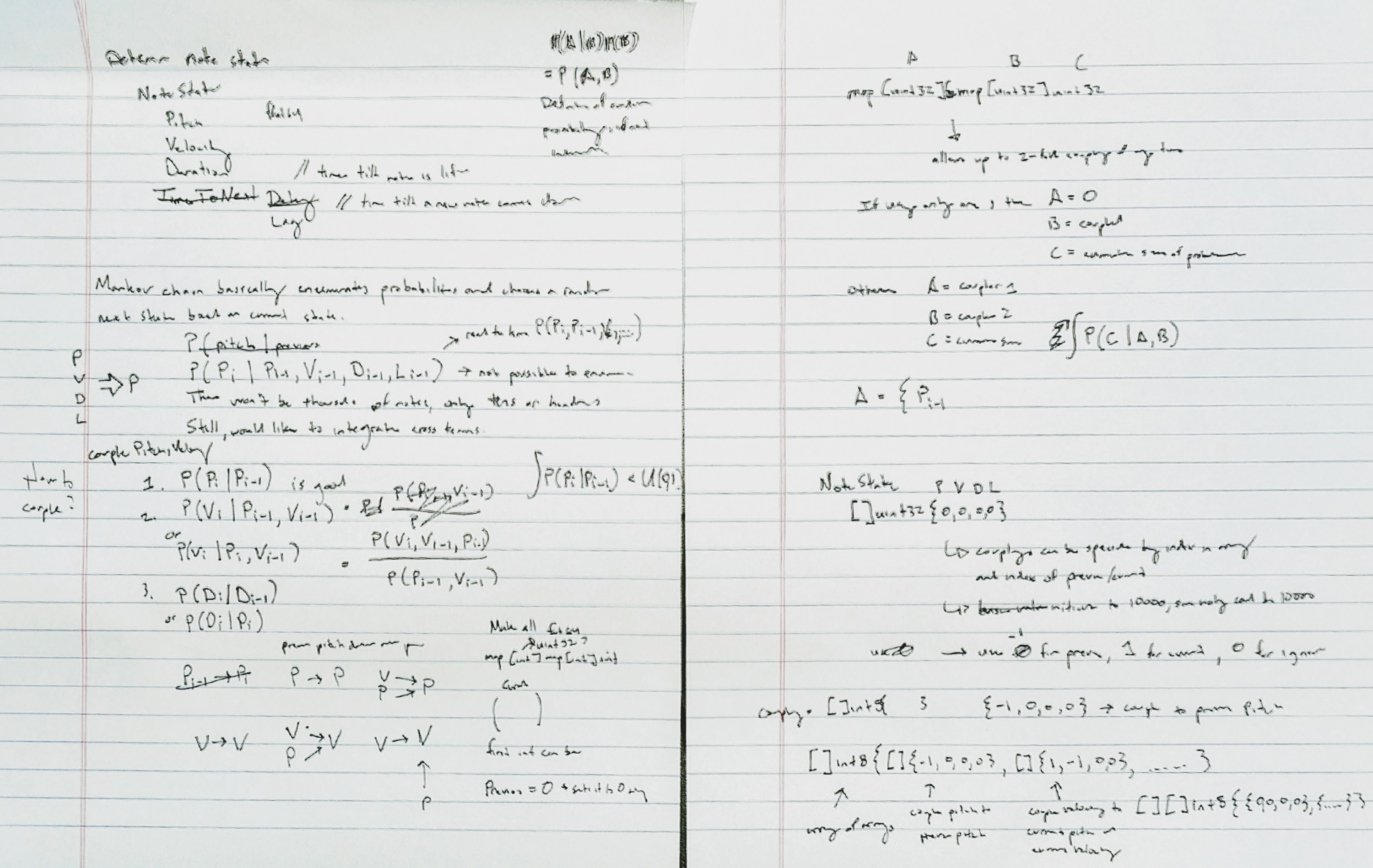
Each time I draw out my idea on paper, it takes about three pieces of paper before my idea actually starts to take form and possibly work.
Programming a Piano AI in Python
Once I had an idea of what I was doing, I implemented everything in . These scripts are built on which has great support for MIDI. The idea is fairly simple - there are two threads: a metronome and a listener. The listener just records notes played by the host. The metronome ticks along and plays any notes in the queue, or asks the AI to send some new notes if none are in the queue.
I made it somewhat pluggable, as you can do variations on the AI so it can be easily outfitted with different piano augmentations. There is an algorithm for simply echoing, one for playing notes within the chord structure (after it determines the chords), and one for generating piano runs from a . Here's a movie of me playing with the latter version of this algorithm (when my right hand moves away from the keyboard, the AI begins to play until I play again):
There were a couple of things I didn't like about this. First, its not very good. At best, the piano AI accompaniment sounds like a small child trying hard to emulate my own playing (I think there are a couple of reasons for this - basically not taking into account velocity data and transition times). Secondly, these python scripts did not work on a Raspberry Pi (the video was shot with me using Windows)! I don't know why. I had trouble on Python3.4, so I upgraded to 3.6. With Python3.6, I still had weird problems. pygame.fastevent.post worked but pygame.fastevent.get did not. I threw up my hands at this and found an alternative.
The alternative is to write this in Go. - which is quite useful since this is a low-latency application. My ears discern discrepancies of > 20 milliseconds, so I want to keep processing times down to a minimum. I found so porting was very viable.
Programming a Piano AI in Go

I decided to simplify a little bit, and instead of making many modules with different algorithms, I would focus on the one I'm most interested: a program that learns in realtime to improvise in the spaces between my own playing. I took out some more sheets of paper and began.
Day 1
Most of the code is about the same with my previous Python scripts. When writing in Go, I found that spawning threads is so much easier than in Python. Threads are all over this program. There are threads for listening to midi, threads for playing notes, threads for keeping track of notes. I was tempted to use the brand new in my threads, but realized I could leverage maps of maps which is beyond the sync.Map complexity. Still, I just made a map of maps that is very similar to another sync map store that I wrote ().
I attempted to make everything classy (pun-intended) so I implemented components (midi, music, ai) as their own objects with their own functions. So far, the midi listening works great, and seems to responds very fast. I also implemented play back functions and they work too - this is pretty easy.
Day 2
Started by refactoring all the code into folders because I'd like to reserve the New function for each of the objects. The objects have solidified - there is a AI for learning / generating licks, a Music object for the piano note models, a Piano object for communicating with midi, and a Player object for pulling everything together.
I spent a lot of time with pen and paper figuring out how the AI should work. I realized that there is more than one way to make a Markov chain out of Piano notes. Piano notes have four basic properties: pitch, velocity, duration, and lag (time to next note). The basic Markov chain for piano notes would be four different Markov chains, one for each of the properties. It would be illustrated as such:
Here the next pitch for the next note (P2) is determined from the pitch of the previous note (P1). Similar for Velocity (V1/V2), Duration (D1/D2) and Lag (L1/L2). The actual Markov chain simply enumerates the relative frequencies of occurrence of the value of each property and uses a random selector to pick one.
However, the piano properties are not necessarily independent: sometimes there is a relationship between the pitch and velocity, or the velocity and the duration of a note. To account for this I've allowed for different couplings. You can couple properties to the current or the last value of any other property. Currently I'm only allowing two couplings, because that's complicated enough. But in theory, you could couple the value of the next pitch to the previous pitch and velocity and duration and lag!
Once I had everything figured out, theoretically, I began to implement the AI. The AI is simply a Markov chain, so it determines a table of relative frequencies of note properties and has a function for computing them from the cumulative probabilities and a random number. At the end of the night, it works! Well, kinda but not really. Here's a silly video of me playing a lick to it and getting some AI piano runs:
Seems like there is more improvement to be made tomorrow!
Day 3
There is no improvement to be made that I can find.
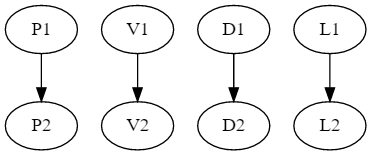
But maybe the coupling I tried yesterday is not very good. The coupling I'm most interested can be visualized as:
In this coupling, the previous pitch determines the next pitch. The next velocity is determined by the previous velocity and the current pitch. The current pitch also determines the duration. And the current duration determines the current lag. This needs to be evaluated in the correct order (pitch, duration, velocity, lag) and that's left up to to user cause I don't want to program in tree traversals.
Well, I tried this and it sounds pretty bad. I'm massively disappointed in the results. I think I need to try a different machine learning. I'm going to make my repo public now, maybe someone will find it and take over for me because I'm not sure I will continue on it.
Day 4
I've been thinking, and I'm going to try a neural net. (commit ).
I just tried a neural net. It went badly, to say the least. I tried several variations too. I tried feeding in the notes as pairs, either each property individually or all the properties as a vector. This didn't sound good - the timings were way off and the notes were all over the place.
I also tried a neural net where I send the layout of the whole keyboard (commit ) and then the keyboard layout that it should transition into. It sounds complicated because I think it is and it didn't seem to work either.
The biggest problem I noticed with the neural net is that it is hard to get some randomness. I tried introducing a random column as a random vector but it just creates too many spurious notes. Once the AI piano lick begins, it seems to just get stuck in a local minimum and doesn't explore much anymore. I think in order to make the neural net work, I'd have to do what Google does and try to Deep learn what "melody" is and what a "chord" is and what a "piano" is. Ugh.
Day 5
I give up.
I did give up. But then, I couldn't help but rethink the entire project while running in the forest.

What is an AI really? Is it just supposed to play with my level of intelligence? What is my level of intelligence when I play? When I think about my own intelligence, I realize: I'm not very intelligent!
Yes, I'm a simple piano player. I just play notes in scales that belong to the chords. I have some little riffs that I mix in when I feel like it. Actually, the more I think about it I realize that my piano improvisation is like linking up little riffs that I reuse or copy or splice over and over. So the Piano AI should do just that!

I wrote down the idea on the requisite piece of paper and went home to program it. Basically this version of the AI was a Markovian scheme again but greater than first order (i.e. remembering more than just the last note). And the Markov transitions should link up larger segments of notes that are known to be riffs (i.e. based off my playing history). I implemented a new AI for this (commit ) and tried it out.
Day 6
What the heck! Someone put my today. Oh boy, I'm not done, but I'm almost done so I hope no one tries it today.
With a fresh brain I found a number of problems that were actually pretty easy to fix. I fixed:
- (I still don't know how this happens ut I check for it now)
And I add command-line flags so its ready to go. And it actually works! Here's some videos of me teaching for about 30 seconds and then jamming:
Day 8
Lots of great feedback on this! Here is which is illuminating.
Notably:
- There is which has a "riffology" algorithm that seems similar to mine.
- Dan Tepfer .
- There are some that could be used to make this better
This is likely not the last day, but if you have more ideas or questions, let me know! Tweet .
]]>(or northern lights) are amazing -- a beautiful display of ionization of the disturbed . Auroras often happen in the dark of the night and their occurrence is random. The best predictions usually only provide an hour's notice. To make sure I can get to see the latest Canadian
]]>
(or northern lights) are amazing -- a beautiful display of ionization of the disturbed . Auroras often happen in the dark of the night and their occurrence is random. The best predictions usually only provide an hour's notice. To make sure I can get to see the latest Canadian auroras, I made a Raspberry Pi Aurora Alarm.
There is a simple way of determining if there is an Aurora in Canada, you just go to . There you will see a graph like this:

From that graph you can see that the Aurora on September 1st, 2017 did not occur until about 11pm. And, even though I was asleep at the time, I was awaken to see the aurora!
My setup is very simple. I have a Raspberry Pi that probes the Aurora with a simple Python function:
import requests
from bs4 import BeautifulSoup
def percent_aurora_right_now():
r = requests.get('http://www.aurorawatch.ca/')
soup = BeautifulSoup(r.text, 'html.parser')
percent_aurora = 0
for span in soup.find_all('span'):
if '%' == span.text[-1]:
try:
percent_aurora = float(span.text.replace('%', ''))
except:
pass
return percent_aurora
and then I have a for-loop that periodically checks if an Aurora has occurred:
import time
while True:
if percent_aurora_right_now() > 70:
alarm()
time.sleep(60)
The alarm() function may have to be changed for yourself. You can do whatever alarm is best -- push notifications, ringing buzzers, etc. Since I am a heavy sleeper, sound usually doesn't wake me up so I made a light alarm. That is, my lights will periodically flash when the Aurora occurs:

I have two PIR sensors at the side of my bed so I can also turn on/off the lights manually. For light automation I'm using .
Here's another picture from the last aurora I saw:

Here's my full code:
]]>
I love discovering new music. Can I make it easier to find new music automatically? This is a beginner's guide for a simple way for implementing a Raspberry Pi server for hyperdiscovery of music. The idea is simple - to setup a server that finds new songs that are related to any song that I like on Spotify or YouTube.
Usually I can find new music by talking to friends, listening to podcasts ( or tuning in to the radio, ). Once, I even ventured into programming my own music discovery service, . Recently I've noticed that Spotify Discover Playlists are doing a great job of supplying fresh and new musicians to discover. I wondered if I could leverage Spotify to help me to supercharge the discovery of music?
Requirements
- IFTTT account, Spotify / YouTube account
- Raspberry Pi
Setup Raspberry Pi
Install packages
The magic of this idea relies on a Python package that I wrote, playlistfromsong. You can . Before starting, make sure you have Python3 installed,
sudo apt-get install python3
Then, to install playlistfromsong, just do:
sudo python3 -m pip install playlistfromsong
In order to get mp3s, you'll also need to . To do this you can or just use :
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-armhf-32bit-static.tar.xz
tar xf ffmpeg-release-armhf-32bit-static.tar.xz
sudo mv ffmpeg-3*/qt-faststart ffmpeg-3.3.2-armhf-32bit-static/ffmpeg ffmpeg-3.3.2-armhf-32bit-static/ffmpeg-10bit ffmpeg-3.3.2-armhf-32bit-static/ffprobe ffmpeg-3.3.2-armhf-32bit-static/ffserver /usr/local/bin/
Either method for getting ffmpeg will work, although the prebuilt option should be much faster.

Once you have everything installed, check to see if it works by typing
sudo playlistfromsong --serve --folder ~/Music
Now you can open up any browser to to play your music.
Setup port-forwarding
In order to setup the webhooks to access your server, you'll need to allow external access to your network by forwarding port 80 on the Raspberry Pi.
First, find your local IP address. To do this, just type
ifconfig
and note down the address that you see.

Now you'll need to enter that address into your router. Open a web browser and log in your router by going to or . There is usually a username and password, usually admin and password. If that doesn't work, do some Googling with your particular router.
Once you log in to your router, find a setting that says "Port Forwarding" and add the address that you saved before as one of the addresses to forward, and for ports use "80" for the internal and the external port. That's it!
Setup DNS
Now you can setup a DNS, don't worry its also easy. First, get your public IP address using
curl icanhazip.com
Note down that address.
Finally, you should and setup a new DNS with whatever name you want and put your public IP address as the target.

Now you have a DNS, YOURNAME.duckdns.org!
Setup proxy server
Finally, you'll need a proxying server. The easiest is . To just do
curl https://getcaddy.com | bash
Then make a new file, named Caddyfile. In this Caddyfile file, put in the following:
YOURNAME.duckdns.org {
proxy / 127.0.0.1:8050 {
websocket
}
}
where YOURNAME is your name you used for the DuckDNS.
Finally, start up your proxying server using
caddy
If it starts without an issue, you can sto the process and then run it in the background using
nohup caddy &
Now you can startup the playlistfromsong server using
nohup sudo playlistfromsong --serve --folder ~/Music &
Now you are up and running! Check out your music server by going to the address you setup with DuckDNS.
Setup IFTTT
Spotify
Lets make an applet that will automaticlaly ask the server to find some new songs for every song we like on Spotify.
For "This" choose "Spotify" and choose the trigger "New saved track". For "That" choose Maker Webhooks and choose the action "Make a web request". For the action field "URL" put in
http://YOURDUCKDNS.duckdns.org/download/4/ {{ArtistName}} {{TrackName}}
For "Content Type" select "application/json". Continue and select "Finish".

YouTube
You can follow the same steps as above for YouTube, with the only diference being the the "This" part of the applet, in which you will select YouTube.
You're done! Now you will download 3 new songs for every song you like on Spotify/YouTube! Enjoy!
]]>What would happen if you made a recipe out of the ingredients for a recipe? What if you repeated this process over and over? I ended up doing this and generated the recipe that starts with the most basic ingredients - dirt, water and sun.
Here are the ingredients of
]]>
What would happen if you made a recipe out of the ingredients for a recipe? What if you repeated this process over and over? I ended up doing this and generated the recipe that starts with the most basic ingredients - dirt, water and sun.
Here are the ingredients of my favorite recipe - a recipe for bread - that I have made almost every week during the past decade:
- 7 1/4 cup flour
- 3 1/2 teaspoon salt
- 3 1/4 cup water
- 1 tablespoon yeast
After thinking about this recipe almost a thousand times, and being inspired by a number of DIY cookbooks, [1] [2] [3] I started wondering - why don't I make flour? and why don't I extract my own salt? Flour and salt are ingredients that I usually buy from the store. However, what would happen if I included the recipe for salt and flour in the recipe for bread? What would the ingredients and instructions look like, and how long would this elongated recipe take to make?

Ingredients are usually restricted to the foods we can buy at the store. Lets remove this restriction and investigate the ingredients of ingredients. In order not to get too far I will define "core ingredients" that are irreducible (we don't need to specify the number of Carbon atoms in a loaf of bread). Core ingredients include soil, sun, water, and living organisms (cow, yeast, chickens).
Recipe recursion
In order to make bread from scratch,[4] we can take each ingredient in the original ingredient list and generate a list of ingredients for that. We can then use - the process a procedure goes through when one of the steps of the procedure involves invoking the procedure itself.

In order to iterate through the recipe as a recursive process, we need a recursive definition of a recipe. For my purposes I created a list of axioms which define the recipe:
- Recipes are ingredients.
- A recipe is composed of reactants, products and instructions. The reactants are a list of recipes needed to complete the reaction. The products are the recipes that result. The instructions explain the transformation (how much, how long, etc.)
- The same reactants and the same instructions always create the same products (note: the inverse is not necessarily true).
Using these axioms, I wrote a which are known precursors to flour, salt, and many other foods.
Ingredients to really make bread from scratch
What is the recipe for flour? It is basically grinding of wheat berries. What is the recipe for wheat berries? It is basically the winnowing of the grain from wheat. What is the recipe for wheat berries? ...
These are the questions that I asked myself over and over again to do a recursive replacement of ingredients in the bread recipe, until the final core ingredients were reached. After this process I obtained the following new list of ingredients:
- Sun
- Plot of soil
- Water source
- 1 gallon seawater
- 3 1/4 cup water
- 1 tablespoon yeast
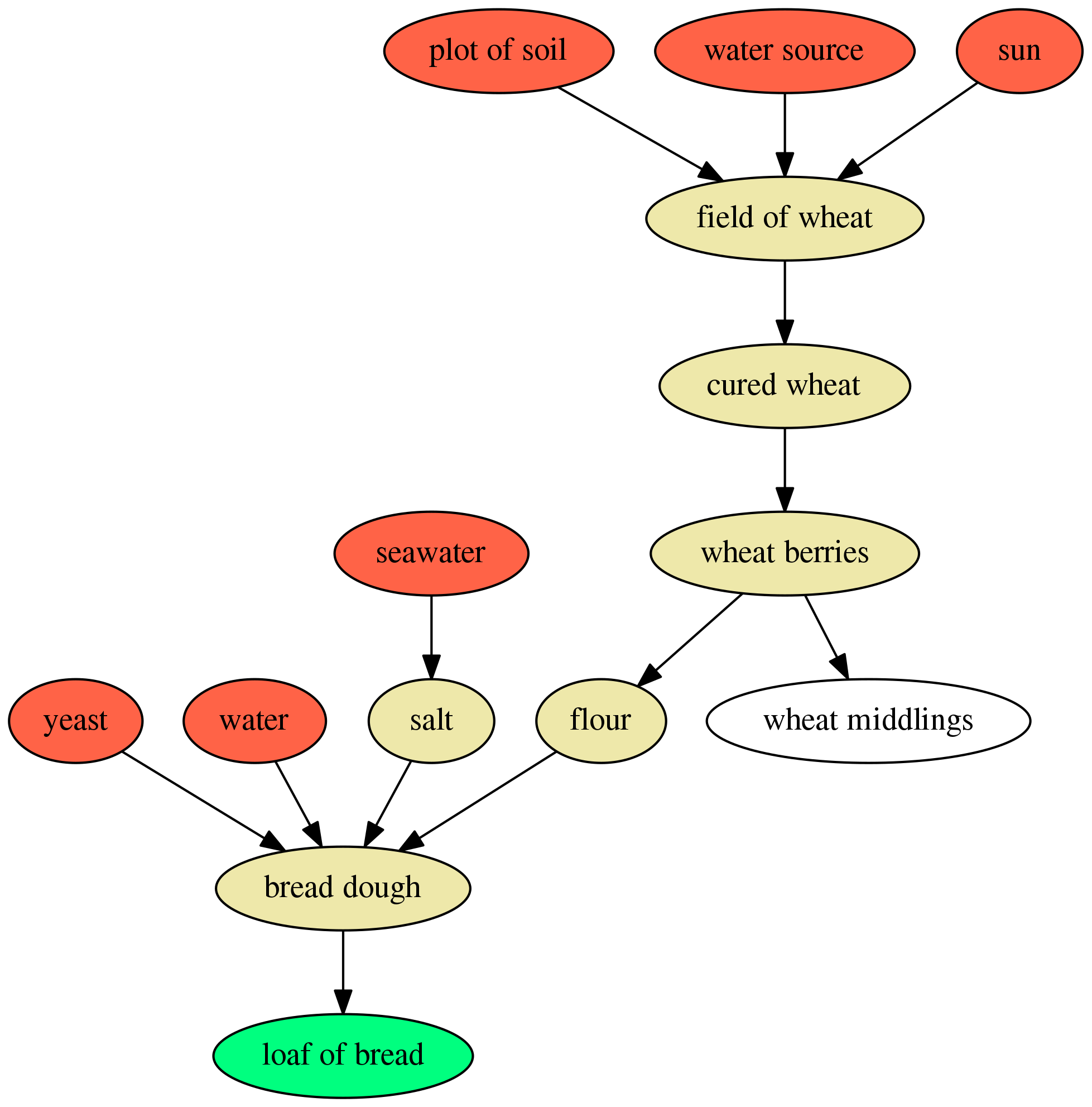
"Flour" has been replaced by "plot of soil, water source, and sun" to grow the wheat and "salt" has been replaced by "seawater." Of course, there is a process for converting these ingredients into the final loaf of bread, which can be visualized in the following:

In the figure, it shows the ingredients (in red) and their intermediate products (in yellow) and the final recipe (in green). It turns out there is a good reason to buy flour at the store - there are a lot of steps and a lot of materials needed to create it! I bet it tastes good, though.
Time to make bread from scratch
Of course, there is also a . Each instruction carries with it the amount of time to create the necessary intermediate product:
- Loaf of bread: 6 hours and 50 minutes
- Salt: 2 weeks, 10 hours
- Flour: Over 4 months
In total, then, making this loaf of bread from the very core ingredients will take 4 months, 3 weeks, 5 days, 14 hours, and 25 minutes (which includes the intermediate processes for grinding and threshing wheat).
Time to make food - the app
I started compiling similar recipes for cookies, tortillas, noodles and found it very interesting to peruse their recipes to the core ingredients.
You can check out different recipes at the website I made with an app to calculate this automatically: .
The tool is open-source, and you can edit the code and add your own recipes: .
I am glad grocery stores exist, because I like making bread every week, and not three times a year.
Alana Chernila (2012). The Homemade Pantry: 101 Foods You Can Stop Buying and Start Making. Clarkson Potter/Publishers. ISBN 978-0-307-88726-9. ↩︎
Jennifer Reese (16 October 2012). Make the Bread, Buy the Butter: What You Should and Shouldn't Cook from Scratch--Over 120 Recipes for the Best Homemade Foods. Simon and Schuster. ISBN 978-1-4516-0588-4. ↩︎
Miyoko Schinner (16 June 2015). The Homemade Vegan Pantry: The Art of Making Your Own Staples. Potter/TenSpeed/Harmony. ISBN 978-1-60774-678-2. ↩︎
Skip this section if you are not a nerd. ↩︎
What if the artist painted a photo, and then used a neural network to render the photo in the style of the same painting? Would it improve the art? I decided to see for myself if neural networks would improve my art.
I started thinking about these questions because I’
]]>
What if the artist painted a photo, and then used a neural network to render the photo in the style of the same painting? Would it improve the art? I decided to see for myself if neural networks would improve my art.
I started thinking about these questions because I’ve been reading about neural networks, and I’ve seen a lot of these neural networks create new works of art by rendering a photo in the style of a famous painting. [1]
Neural networks are complicated, but worth reading about,[2] but namely it is a system composed of computational “neurons” linked up in a way that is similar to the brain that try to solve problems. The connections between these neurons are given specific weights, as they learn how to classify one thing from another. Groups of neurons work in tandem to determine specific features (i.e. the make of the car vs. the color of the car).

A neural network understands a painting by looking at its specific features. Luckily, paintings have two main transferable features: content and style. When we look at a painting, like Jean-Jacques Rosseau’s cat, we experience both the content and the style of the painting simultaneously, but we can (usually) identify them separately. Content is the the subject of that the painter is trying to convey (the cat), where style is the manner which they convey it (bold colors and strokes, awkward proportions in the legs). Rosseau cannot fool us into thinking he did not paint a cat, even though he did an awfully strange representation of it.
Recently, a paper by Gatys, Ecker, and Bethge[3] was able to show that representations of content and style are separable. They used an algorithm that makes use of a convolutional neural network[4] and demonstrated the separability of content and style by transferring the style of a Starry Night by Van Gogh (i.e. the iconic swirls of dark blue pastel) to a photograph of the Neckarfront houses of Tubingen, Germany.

The genius of this paper was to leverage neural networks for classifying local features in images to extract the representations of content. The neural network used here is the VGG-Network by Simonyan and Zisserman which is the state-of-the-art for identifying things in images.[5] To transfer Starry Night to Neckarfront, Gatys, Ecker, and Bethge simply exploited the neural network to copy the set of neurons that finds representations of content (which parts of the image are the “building”), and then using another layer that extracts the style, or texture (i.e. non-features that are local in context, like the swirls in Van Gogh’s painting).
Making a neural network to paint with my style
To make a neural network paint like me, I will first select a photo and then paint the photo myself. Then I will use my painting to generate a neural network rendering from the original photo. That is, I will use the style from the painting I create and transfer it to the content of the photo that I used to create the painting. Technically speaking, I used the algorithm from Gatys, Ecker, and Bethge, as coded by compiled with the CUDA backend to use on a GTX 1080Ti.
For example, I can start with a photo of a heron.

Then, I create my own Gouache painting of the photo.

Finally, I transfer the style of my painting to the content of the photo to create a neural network rendering.

The results are astounding. The neural network uses my color palette and some of my strokes, but seems to suppress a lot of my mistakes and more precisely articulates the original photo. For example - the wings that I painted are very unordered and sloppy, but the neural network used the original wings and used the idea of my painting to fix them.
The neural network becomes the teacher
The heron is not an outlier. Almost every painting I create can be re-imagined by a neural network to be rendered as a much cleaner and more professional painting.[6] The machine makes a professional out of a novice.
Here are more examples showing the original photo (left), my painting of the photo (middle) and the neural network rendering of the photo using the style of my painting (right). After looking at them quite a bit, I can see some simple things I can do to improve my own painting.
Click on any of the paintings to see them in full resolution.
Cat
I like how the neural network put more white around the eyes and also patches of gray to shadow the eye and mouth. I could have also been more liberal with my striping on the arm.

Bison
Though I like the original watercoloring better, I think the neural network does a better job on the bison's hair on its head - using a reddish color and blending it out.

Koala
My mistakes fixed by the neural network - I made the yellow around the baby koala is too wide, and its head too light. I love the neural network ears - they aren't outlined so it gives them a lighter touch, and the fur on the big koala has more brush strokes which makes it more dynamic.

Deer and cat
I also think my rendition for the watercolor is very good, although I wish I had gotten the proportions better, as it looks a lot nicer. Also a thinner outline would have been better, as the neural network does. I also love how the neural network reinterprets the background - putting in more orange and gray which complements the deer and cat.

Fox
I had a lot of trouble on the tail of this fox, and the neural network has a great way of doing it - simply dab the outside and then blend in the grey and red. I also love the purple on the fox hind leg, which I was not bold enough in bringing out on my own painting.

Dog and owl
I love my painting here as well, but the proportions are wrong, my dog is far to narrow. I also could have shadowed the snout a little differently, to make the sides of the head stand out more, like in the neural network.

Mountain Goat
A white animal is very difficult for me, but I think the neural network shows a possible solution: focus on the middle with gray/blue and then on the outside with yellow.

Conclusion
It seems a computer is better at painting than I am.
But seriously, this is a rather neat illustration of the separation of content and style. In the future I would like to instead train my own neural network with a corpus of my photos and illustrations to transfer my style to photos. In this case, I imagine it will be agnostic to content but will merely encode my style. I have to learn how to train neural networks first, though.
Some great resources on Github are and . ↩︎
written by Michael Nielsen which gives a great introduction to neural networks. ↩︎
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. "A neural algorithm of artistic style." arXiv preprint arXiv:1508.06576 (2015). ↩︎
A convolutional neural network is a special kind of neural network that links up the computer neurons in a way that mimics how the visual cortex operates. ↩︎
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). ↩︎
The cases where the neural network did poorly was in paintings where I left the background completely white. ↩︎
In most cases, code is a tool. Sometimes its hard to remember that. Sometimes code is a tool to help you code, but in the best case code bridges something in reality to enhance it.
What is the purpose of technology? Technology generally serves to enhance the world around us.
]]>
In most cases, code is a tool. Sometimes its hard to remember that. Sometimes code is a tool to help you code, but in the best case code bridges something in reality to enhance it.
What is the purpose of technology? Technology generally serves to enhance the world around us. Glasses enhance eyesight. Cars enhance locomotion. Soap enhances the immune system (by providing an external one). Pots/pans and fire enahnces digestion. Computers and code enhance knowledge, and memory.
Most often, my favorite code is the code that helps you keep memories. Here are some of them:
gojot
I have tried and tried to keep a journal. I constantly find that physical journals become cumbersome to move and keep track of, but then I find that the same is true of software tools. That is why I think one of my favorite pieces of software is one that I wrote myself - gojot, which is a simple and fast way to keep a decentralized and encrypted journal.
cowyo
I have two types of journals typically - one for short term and one for long term. Both are spread out on tons of pieces of paper and apps on my phone and on my computer. My attempt to centralize these became cowyo which is a extremely simple wiki / blank space for me to write notes, make todo lists or keep track of lists. Its just an online notepad really, but the simplicity it what endears it to me. Also, its another thing that I made, so I know exactly how it works and how to fix it and I know that I will own all the data I put in it, forever.
git
I had a brief stint with svn and then I gave up on version control. I loved the idea of it though, and performed rudimentary backups that somewhat served as a version control. Now that I grasp and understand git, I keep almost every project I do (papers, research, code) in a repo and host it on one of the many cloud controls. Though git is a tool for coding, it helps me keep track of my memories and actions.
What if Moby Dick was written as a sonnet, or a limerick, or as a haiku? I wrote a quick program that can take an orginal text like Moby Dick and try to do just that.
Here are some of the examples:
Haikus
till after sunset]]>
the clothes that the

What if Moby Dick was written as a sonnet, or a limerick, or as a haiku? I wrote a quick program that can take an orginal text like Moby Dick and try to do just that.
Here are some of the examples:
Haikus
till after sunset
the clothes that the night had wet
haven't seen him yet
that behind those forms
he enters the sign of storms
a field strewn with thorns
Limerick
thou art a full ship and homeward bound
he lays it against a gloomy ground
the whole calamity
that's christianity
whaling scenes to be anywhere found
Sonnet (partial)
i here saw but a few disordered joints
where his bayonet rays moved on in stacks
this carpenter was prepared at all points
which in a voyage of four years perhaps
consider also the devilish brilliance]]>
rushing among the boats with open jaws
this great whaling house was in existence
ambergris is supposed to be the cause
I am trying to find the best co-operative non-expansion games that require two or more players and are generally easy to set-up and play and are resistant to quarterbacking. Here's the ones I found.
There are tens of thousands of board games now. Luckily there is a great website,
]]>I am trying to find the best co-operative non-expansion games that require two or more players and are generally easy to set-up and play and are resistant to quarterbacking. Here's the ones I found.
There are tens of thousands of board games now. Luckily there is a great website, to find new board games. However, while this website has decent options for searching, I was searching for games of a particular variety where the website did not quite help me.
"" is the phenomenon where whoever has the best knowledge of the game drives the game, transmuting a co-operative game into a solo-game that the others watch. I want to make sure that the two+ players need to make independent decisions to pursue the common goal. Also, I would like to know which games can be played without spending 20 minutes to learn the rules (I sometimes play in a cafe where you pay by the hour). And the game should be fun!
Since does not have a search button for finding these types of games, I pulled the data from and made a quick search with my criteria (no expansions, min players > 1, easy set-up, high scoring). The code is . Some of the games I expected (Hanabi) but there are plenty more that I don't know, that I am excited to try. The search seems to work since the typical quaterbacking-problem games are left off (Pandemic, Forbidden Desert).
Here are the top 25 easy-to-play non-expansion co-operative games sorted by their user ratings:
Top 25 easy-to-play co-op games
| Rank | Game | BGG Score | Play time (minutes) |
|---|---|---|---|
| 1 | 7.82362 | 90 | |
| 2 | 7.34697 | 42 | |
| 3 | 7.12786 | 25 | |
| 4 | 7.07644 | 45 | |
| 5 | 7.07012 | 30 | |
| 6 | 7.00534 | 60 | |
| 7 | 6.96669 | 60 | |
| 8 | 6.67126 | 15 | |
| 9 | 6.60252 | 45 | |
| 10 | 6.54911 | 10 | |
| 11 | 6.54536 | 30 | |
| 12 | 6.35747 | 45 | |
| 13 | 6.35567 | 15 | |
| 14 | 6.29748 | 25 | |
| 15 | 6.24817 | 20 | |
| 16 | 6.17016 | 60 | |
| 17 | 6.16536 | 30 | |
| 18 | 6.14583 | 90 | |
| 19 | 6.12875 | 30 | |
| 20 | 6.10003 | 15 | |
| 21 | 6.08654 | 15 | |
| 22 | 6.01168 | 60 | |
| 23 | 6.00247 | 60 | |
| 24 | 5.99723 | 60 | |
| 25 | 5.97854 | 45 |
Top 25 hard-to-play co-op games
| Rank | Game | BGG Score | Play time (minutes)</t h> |
|---|---|---|---|
| 1 | 8.48977 | 60 | |
| 2 | 7.79663 | 90 | |
| 3 | 7.71266 | 210 | |
| 4 | 7.64052 | 300 | |
| 5 | 7.36217 | 30 | |
| 6 | 7.22753 | 120 | |
| 7 | 7.04317 | 80 | |
| 8 | 6.90721 | 90 | |
| 9 | 6.6969 | 120 | |
| 10 | 6.68663 | 90 | |
| 11 | 6.39541 | 120 | |
| 12 | 6.26096 | 240 | |
| 13 | 6.17533 | 45 | |
| 14 | 6.01353 | 90 | |
| 15 | 5.997 | 90 | |
| 16 | 5.98868 | 90 | |
| 17 | 5.97452 | 60 | |
| 18 | 5.92203 | 90 | |
| 19 | 5.91802 | 5400 | |
| 20 | 5.8873 | 120 | |
| 21 | 5.87782 | 90 | |
| 22 | 5.79778 | 120 | |
| 23 | 5.78058 | 120 | |
| 24 | 5.73843 | 100 | |
| 25 | 5.69853 | 0 |
Top 25 non-co-op easy-to-play games
| Rank | Game | BGG Score | Play time (minutes) |
|---|---|---|---|
| 1 | 8.0275 | 30 | |
| 2 | 7.79794 | 15 | |
| 3 | 7.74981 | 30 | |
| 4 | 7.7068 | 60 | |
| 5 | 7.6964 | 30 | |
| 6 | 7.67122 | 30 | |
| 7 | 7.66509 | 45 | |
| 8 | 7.60759 | 30 | |
| 9 | 7.5735 | 20 | |
| 10 | 7.57188 | 30 | |
| 11 | 7.55223 | 30 | |
| 12 | 7.49889 | 20 | |
| 13 | 7.48316 | 60 | |
| 14 | 7.43473 | 30 | |
| 15 | 7.41992 | 30 | |
| 16 | 7.41511 | 60 | |
| 17 | 7.41307 | 60 | |
| 18 | 7.39185 | 60 | |
| 19 | 7.38991 | 60 | |
| 20 | 7.3886 | 60 | |
| 21 | 7.37252 | 60 | |
| 22 | 7.36176 | 60 | |
| 23 | 7.35301 | 60 | |
| 24 | 7.33588 | 45 | |
| 25 | 7.32831 | 60 |
Top 25 non-co-op hard-to-play games
| Rank | Game | BGG Score | Play time (minutes) |
|---|---|---|---|
| 1 | 8.30771 | 240 | |
| 2 | 8.22189 | 180 | |
| 3 | 8.15133 | 150 | |
| 4 | 8.14493 | 240 | |
| 5 | 7.99572 | 90 | |
| 6 | 7.98424 | 150 | |
| 7 | 7.96296 | 180 | |
| 8 | 7.92672 | 240 | |
| 9 | 7.92639 | 90 | |
| 10 | 7.89813 | 120 | |
| 11 | 7.8648 | 120 | |
| 12 | 7.85757 | 200 | |
| 13 | 7.83876 | 150 | |
| 14 | 7.82252 | 45 | |
| 15 | 7.81577 | 240 | |
| 16 | 7.81077 | 180 | |
| 17 | 7.80487 | 150 | |
| 18 | 7.80003 | 90 | |
| 19 | 7.79425 | 90 | |
| 20 | 7.75722 | 100 | |
| 21 | 7.75487 | 120 | |
| 22 | 7.72802 | 100 | |
| 23 | 7.72728 | 150 | |
| 24 | 7.70748 | 300 | |
| 25 | 7.68936 | 240 |
Alternate title: why I made a book recommendation service from scratch. Basically I found that all other book suggestions lacked so I made something that actually worked.
I read about 30–40 books a year. Not to be morbid, but this equates to only reading about 3,000 books in
]]>
Alternate title: why I made a book recommendation service from scratch. Basically I found that all other book suggestions lacked so I made something that actually worked.
I read about 30–40 books a year. Not to be morbid, but this equates to only reading about 3,000 books in my lifetime. Since there are millions of books that exist,[1] it means that I can only consume a fraction of a fraction of a percent of them. This exceptionally limited scope of my eventual reading repertoire is my motivation to find a systematic method to acquiring good book suggestions.
Current recommendations are bad
I’ve noticed that there are five major problems that prevent me from continuing to use the major services like Goodreads and Amazon for book recommendations.
Problem 1: Suggested books are the wrong genre
One of the best approaches to finding a new book to read is to look for books with a similar genre. The genre of Weaveworld is classified as “dark fantasy horror” according to Amazon, which is a good approximation of the book. And since this is a pretty specific genre it should provide good recommendations that are similar, right? Unfortunately, no.
On Amazon I can lookup the top sellers for this genre, “dark fantasy horror,” and try to find a book from those. Here is what I see, looking at the top six sellers on this particular day from Amazon:

If the titles and the book covers don’t give it away (although you should not judge a book by its cover), three of the six top sellers for the “dark fantasy horror” genre have descriptions that contain phrases like “sexy”, “adult urban” or “a budding romance.” I do not judge people that like these books, but I would argue that these are in the wrong category. Even though these might have elements of “dark fantasy horror”, it seems that their main themes are adult. (You are probably thinking, this can be solved using multiple genres. You are right, read on!).
Basically the top sellers from Amazon for the genre “dark fantasy horror” contains little, if any, actual “dark fantasy horror” and its a waste of time to go browsing through it.
Problem 2: Suggested books are sequels
Instead of looking at top sellers, one can also simply search the genre. This will run into another problem. Here are three sequential results on the first page of searching for “dark fantasy horror” from Amazon:

Of course, one of these has “steamy sex” as a description (Problem #1), but even more problematic is that all three of these books are sequels. I would never recommend you to read a sequel before reading the first book, with exception of a few books — like is a great one to read no matter what. Currently, though, you have to trudge through a bunch of sequels because there is no way to filter them out on Amazon or Goodreads.
Problem 3: Book suggestions come from only one (or a few) authors
If we do a similar search on Goodreads, we will find another problem. Here are the top results for searching the genre “dark horror fantasy”:

These search results are also problematic in terms of providing good recommendations as four of these six books have the same author! The number of distinct authors increases very slowly as you go through the search results from Goodreads. This is not helpful because I believe you should be recommending a new author just as much as a new book. I don’t need a recommendation service to just go look up books from the same author.
Problem 4: Internet people rarely share similar tastes
I enjoy when friends give me recommendations since I have a good idea of whether (or not) we share taste in books and I can easily decided to trust them (or not). I don’t enjoy having recommendations from random people based on their web history, since you never know if someone just read some book and secretly didn’t like it but told the Internet they did.
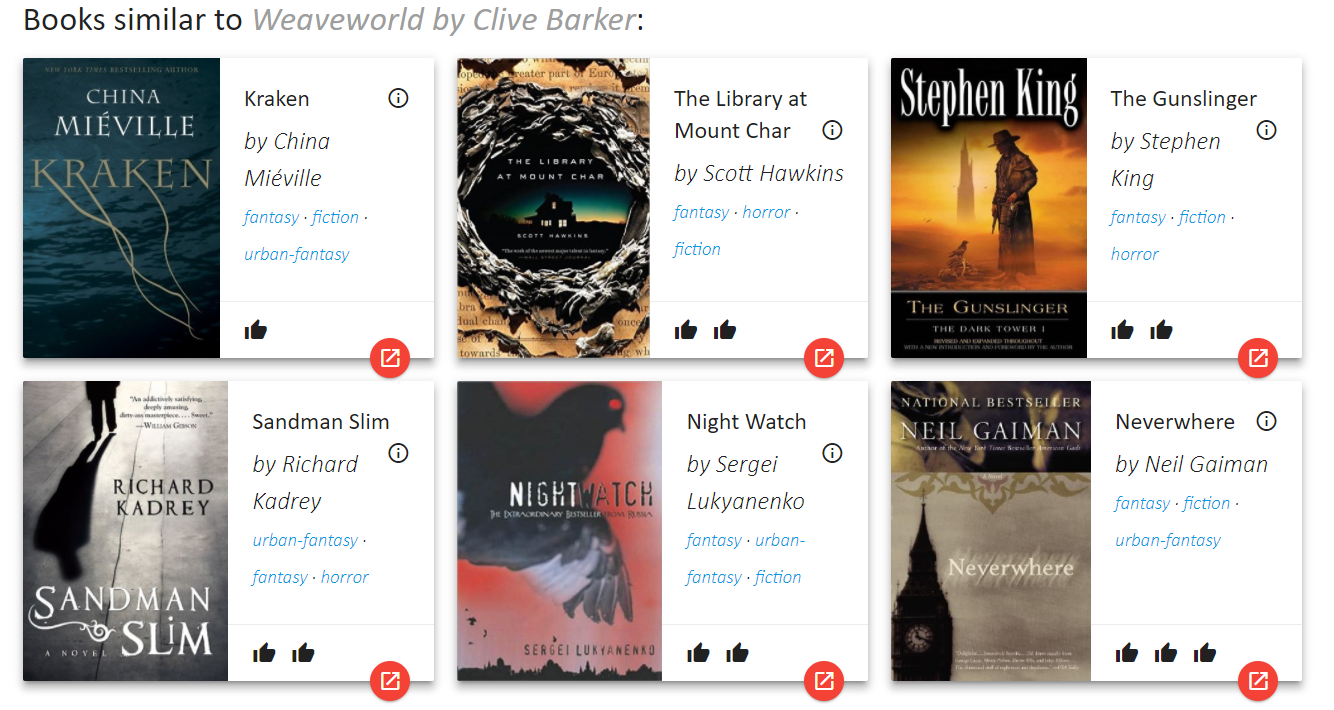
For some special people these types of recommendations might work (e.g. if you are just starting out on a genre). But usually these type of results are derivative. Amazon will show me books from “Customers who bought this item” and Goodreads will show me “members who liked X also liked” but the results are similar. For example, here are Amazon’s:

The first two books are possibly good recommendations, until you see that both those books are two of the most popular books in the genre of all time. So if you are new to the genre they are good, but I am not, so of course I have read those before. The other books are both books from the author of the Weaveworld, so I do not want those suggestions (Problem #3).
I want a new recommendation from a different author.
Problem 5: Recommendations are hard to parse
You can certainly find a good book suggestion from Goodreads or Amazon, but it might take a long time. It seems that these sites are designed to keep you looking, in fact, because they have an incentive to elude you from getting complete information quickly. Because of this, I have given up with Goodreads and Amazon. There are other services, like , but this hardly provides similar recommendations for Weaveworld by Clive Barker, as .
In light of this, I propose a simple solution.
My ideal book recommendation service
To make a book recommendation service that actually works, I would avoid Problems #1–3 using simple filters. And it will avoid Problem #5 by being quick and simple — no sign-ups, no ads, no hard-to-navigate user interface. It would avoid Problem #4 by using probabilistic genres.
What are probabilistic genres?
What I call a probabilistic genre could be called many things: the book’s genome, the hierarchical classification, etc. The basic idea is that each book has multiple genres with different weights or emphasis.
The probabilistic genres can be calculated using the Goodreads API. For example, Weaveworld :
<shelf name=”to-read” count=”6532"/>
<shelf name=”fantasy” count=”1017"/>
<shelf name=”currently-reading” count=”711"/>
<shelf name=”horror” count=”684"/>
<shelf name=”fiction” count=”280"/>
<shelf name=”favorites” count=”255"/>
<shelf name=”owned” count=”104"/>
<shelf name=”clive-barker” count=”97"/>
<shelf name=”dark-fantasy” count=”62"/>
<shelf name=”default” count=”61"/>
<shelf name=”books-i-own” count=”60"/>
<shelf name=”sci-fi-fantasy” count=”46"/>
<shelf name=”science-fiction” count=”34"/>
<shelf name=”sci-fi” count=”31"/>
While Weaveworld is defined by Amazon and Goodreads to be “dark fantasy horror”, according to these shelves (and ignoring non-genres) it is actually mostly fantasy (1,017 counts), horror (684 counts), with a little science fiction (~100 counts). It might be better classified as “fantasy horror fiction sci-fi.”
Just for comparison, to see the benefit of these probabilistic genres, recall the very first recommendation from Amazon in the genre “dark fantasy horror”: Agent of Enchantment by C.N. Crawford? Here are :
<shelf name=”urban-fantasy” count=”8"/>
<shelf name=”fantasy” count=”6"/>
<shelf name=”paranormal” count=”4"/>
<shelf name=”magic” count=”3"/>
<shelf name=”fae” count=”3"/>
<shelf name=”favorites” count=”3"/>
<shelf name=”maybe” count=”3"/>
<shelf name=”netgalley” count=”3"/>
<shelf name=”mystery” count=”2"/>
<shelf name=”fairies” count=”2"/>
<shelf name=”adult” count=”2"/>
<shelf name=”romance” count=”2"/>
Clearly, Agent of Enchantment would be better classified as “urban fantasy paranormal mystery adult romance” and it is definitely not similar to “fantasy horror fiction sci-fi” of Weaveworld. In fact, its not even close to the genre of point “dark horror fantasy”, because “horror” doesn’t even show up.
Anyways, I digress. These genres can be determined in a more quantified way by calculating the percentage of each genre (ignoring non-genres) so Weaveworld might be approximated as “45% fantasy, 25% horror, 15% fiction, 6% dark fantasy, 5% science fiction and 4% sci-fi fantasy”, based solely on the counts. To find a recommendation then, I just need to go through books with similar genres and calculate a metric that determines the “distance” between the two books. Once I have a list of distances, I can sort them and find the closest distances and perform the filtering I want (no similar authors, no sequels).
Coding my solution[2] {#coding-my-solution1}
Now that I had my basic plan of attack, I decided to implement the ideas as a simple single-page app (SPA). I found a cheap domain name: booksuggestions.ninja and made a cute logo and set to work.
Step 1: Collecting data
I first collected the data for books from Goodreads API and the Google Books API. This took several weeks.
Realistic ratings from Google Books were determined using a which accounted for the average rating count and value in that genre. I especially used genre-specific ratings because I have seen on Amazon how all the “romantic” novels have absurdly high recommendations which means that certain books may self-select groups of people who are predisposed to rating things a common way.
Step 2: Processing similarities
I wrote a program in to process the similarities. This program is pretty simple — it loads all the books into a giant map, and then for each book it traverses the map and calculates the distances from it to every other book. The distances are computed as the total sum of the absolute difference between two of the same genres. Once the distances are computed, it sorts the list and outputs a file containing its matches. Simplicity does not equate speed in this case, as the matching takes about 24 days to calculate. Luckily I can use , so it only takes 3 days, during which my looks like this:

I wish I had checked for bugs before running this, because after running it I found I had to start over and wait another 3 days to calculate the similarities a second time.
Step 3: Building a database
After determine the book-to-book similarity, I wrote another Go program to generate a SQL file for a database. The SQL file is used to construct the database with the command (the is a cool trick to see how long it takes to push the data into the DB). Of course, this could have been done in Go as well but I’m lazy.
Speaking of laziness, I then wrote a Python script to generate a bash script that would generate text files that contain entries from common searches (e.g. searches for the best books from a specific genre). Gotta love that meta-programming!
Step 4: Building a website
I built a backend in Go using . The back-end basically performs SQL queries in the database. The front-end is a webpage with a text box to enter search for books or select a genre. The communication with the backend is written in jQuery. I realized I could have used this opportunity to learn React + Redux, but I just wanted to do the front-end fast rather than well. Even so, I learned some neat things and ended up building my own little so you can use the back arrow in the app - it’s a small detail but it makes it feel much better.
Step 5: Handling user input
I quickly realized that I would need an approximate string matching library to help me find the book that a user is searching. This is a particulary daunting task since there are over 2.5 million books and Levenshtein would be far to slow (it can takes tens of seconds!). I ended up writing my own little algorithm that is based off a bag-of-words approach, and given the right parameters it can find matches in less than 30 milliseconds! I actually made this part of the program a microservice because it eats up a lot of RAM so I do not want to run multiple instances of it if I choose to. The microservice and the Go library are available .
Step 6: Try it out!
Now that I had the technical details implemented, I went to my new website and tried to find a suggestion!
Result: What book should I read after Weaveworld?
To get a baseline I asked real people what I should read next and they suggested: Imagica by Clive Barker, stuff by Neil Gaiman books,* The Talisman by Stephen King. *I’ve already read all of Neil Gaiman books, and have somehow missed out on reading any Stephen King. Still, these were pretty good recommendations from people familiar with the book I’m reading.
After getting real recommendations, I turned to the Book Suggestions Ninja and entered Weaveworld by Clive Barker. The .
The top recommendation is The Library at Mount Char by Scott Hawkins. This sounds like a great recommendation - a "horrifying and hilarious" book about gods and secrets with weird and esoteric characters. The other recommendations are great too - Imajica and Night Watch are both books I've been interested. The Stand is also a frequent recommendation. Further down there are great books I've read before, like The Lies of Locke Lamora and The Warded Man, but for the most part all of these books are really good new recommendations. Looks like I will have plenty of reading to do!

Choosing my next book to read
I chose two books to read - the top recommendation and the 19th suggestion which are both listed as SO good. The top recommendation, The Library at Mount Char by Scott Hawkins was really SO good in that I couldn't put it down and finished it in four days. The other book is Hard Magic by Larry Correia which has these elements of magical realism and horror and fantasy that I liked about Weaveworld. This is impressive that the suggested books stay so close to the original, even this far down the list!
I like these recommendations, a lot. They get straight to the point and have some books that I know are good, which makes me think the rest could be good too. These recommendations literally took me 6 seconds of searching and 2 minutes of scanning the web page.
Conclusion

The result of this rather long article and four weeks of work and 1,600 lines of code is .
No recommendation will probably ever be better than your friends. However, if you carefully analyze genres, look at a diverse list of authors, and filter out sequels, you can find great recommendations. This is what my app, , tries to do — maybe it will work for you too? If it does, please let me know, tweet me (tweet me if it doesn’t work, too).
In any case, I found a new book to read after finishing Weaveworld which is all I could really ask.
The best .vimrc is from :
set nocompatible
set backspace=2
func! WordProcessorMode()
setlocal formatoptions=1
setlocal noexpandtab
map j gj
map k gk
setlocal spell spelllang=en_us
set thesaurus+=/Users/sbrown/.vim/thesaurus/mthesaur.txt
set complete+=s
set formatprg=par
setlocal wrap
setlocal linebreak
set foldcolumn=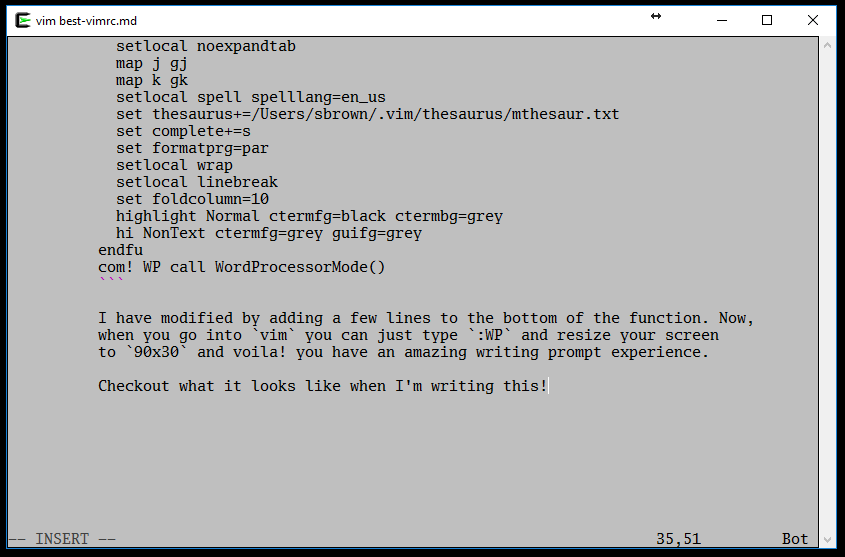
The best .vimrc is from :
set nocompatible
set backspace=2
func! WordProcessorMode()
setlocal formatoptions=1
setlocal noexpandtab
map j gj
map k gk
setlocal spell spelllang=en_us
set thesaurus+=/Users/sbrown/.vim/thesaurus/mthesaur.txt
set complete+=s
set formatprg=par
setlocal wrap
setlocal linebreak
set foldcolumn=10
highlight Normal ctermfg=black ctermbg=grey
hi NonText ctermfg=grey guifg=grey
endfu
com! WP call WordProcessorMode()
I have modified by adding a few lines to the bottom of the function. Now, when you go into vim you can just type :WP and resize your screen to 90x30 and voila! you have an amazing writing prompt experience.
Checkout what it looks like when I'm writing this!

tldr;
One year ago, it wasn't possible for me to slim down my programs to allow the Raspberry Pi to run one web app. One year later, I am hosting 4 web apps on my Raspberry Pi thanks to knowledge and experience that comes with time (and lots of playing)
]]>tldr;

One year ago, it wasn't possible for me to slim down my programs to allow the Raspberry Pi to run one web app. One year later, I am hosting 4 web apps on my Raspberry Pi thanks to knowledge and experience that comes with time (and lots of playing).

"There is no perfection, only beautiful versions of brokenness" - Shannon L. Alder
About one year ago I wrote my first web app, the Music Suggestions Ninja. It wasn't fancy and it wasn't fast. But it worked and . I wrote it in Python. It used very little dependencies, but only because I didn't know about any of the great Python packages that I know of now. To make it work, I ended up writing a homegrown fuzzy string matching library and I learned a lot about NGINX loaded balancing. Still, it suffered massively in production.
But it worked. Its been running for about a year now on my schools fancy virtual machine - a 2-core Intel Xeon 2.70GHz loaded with Ubuntu, 2GB of memory and 20GB of disk space. Since I would eventually lose access to this fancy virtual machine, I decided to rewrite this program knowing what I know now - so that it functions perfectly on a Raspberry Pi 2 with a third the computing power, half the disk space and half the memory.
We can rebuild. We have the technology.
Where to start to transform my old web app into something leaner and faster? Well, when I took a look at the old site ( and ), it carries a bunch of junk no one cares about or uses. No one reads the blog, or the changelog, or the about page, or the terms of use, or the contact info. No one uses the API. So, out they go. Once I removed the junk, I realized there were only two components left - generating band names from searches and saving playlists. Simple.
I rewrote everything in my new favorite language, Go following some generic principles. It took about 3 hours. Luckily, I had just ported my homegrown fuzzy string matching library from Python to Go which had a 10x speed improvement already. From there I followed the same methods I used to write to add routes and process inputs. Everything else is basically the same, except the backend database is now BoltDB instead of MySQL.
Benchmarking the new vs old
I benchmarked both versions of Music Suggestions Ninja, the old and new, by searching for a band called "Coldpla" (which is fuzzy matched to "Coldplay"). The disk space was measured using ds -sh ./, the memory usage was measured using free -m before and after stopping program, and the speed was measured using by simulating 300 users hatching 10 users/second. Here are the results:
| Version | Disk space | Memory usage | Speed |
|---|---|---|---|
| 480 MB | 580 MB | 1 req/sec | |
| 140 MB | 5-20 MB | 20 reqs/sec |
Basically, my **new version is 20x faster and uses 70% less disk space and 97% less memory.** *Note: the improvement is not strictly due to Python vs Go.* A lot of the improvement comes from implementing everything in a much smarter way (which comes from experience and is not language specific). E.g. I am using more DB files instead of loading into memory, I am skipping `for` loops that were unnecessary and using more REGEX. ]]>
tldr; use databases - but index them; take advantage of common utilities or learn Go
I like to write web apps and host them myself on the Pi. I'm no code ninja. I write in Python which is a great language, but not the fastest or memory efficient. To overcome
]]>tldr; use databases - but index them; take advantage of common utilities or learn Go
I like to write web apps and host them myself on the Pi. I'm no code ninja. I write in Python which is a great language, but not the fastest or memory efficient. To overcome liabilities I've found some tricks. I'm sure these are probably obvious to most people so I'd love thoughts about other ideas for optimization!
The problem: minimize RAM usage while maximizing speed
A pi has < 1 GB of memory and its never going to be as fast as a modern computer. Its crucial to minimize the memory so that you can have multiple apps on one pi (or lots of forks of one app) and its crucial maximize speed so the pi is not noticeably slower than a modern computer.
Minimize RAM: Use databases, index everything
For all my web apps, I typically have a big dataset that I need to load as a resource, and while its tempting to load into memory to get huge speedups, I usually have to resort to a database so that I can keep things on disk and still get fast access.
Sqlite3 is great for databases. A great trick I've learned is to index your searches and try to use . Tons of performance with little overhead.
Plain text files sometimes come in handy as well. A trick for accessing data from a text file is to precompute the position of the data in the file and store the position in a keystore. Keystores can be fast, and seeking in a text file is faster than parsing it each time.
Maximize speed: use CLI utilities, or use a fast language (last resort)
I'm no coding ninja - I avoid writing in C and have not even attempted assembly. I like Python. And usually I don't care whether my 9 millisecond Python function would run in 10 microsecond using C++. But for web apps, I do care if things start taking >1 second - which starts to happen when you iterate over 1,000,000 of something. This forces me to try to be more clever.
For simpler things I find there is a lot of power in finding CLI utility alternatives (e.g. , grep for searching, agrep for fuzzy searching, wget for web). These can go a long way, even after accounting for the extra time to call the subprocess.
For harder cases, Go has become my best friend as I find its straight forward to port to Python code, its super lightweight (~10-20 MB RAM per executable) and its fast. Usually at least a 10x speed up from Python. This can make the difference between a noticeable 1 second delay and an imperceptible 100 millisecond delay in web rendering.
]]>This closely follows but also includes the Pi dependencies:
sudo apt-get install swig oss-compat pulseaudio libpulse-dev automake autoconf libtool bison python-dev
For all benchmarks I recorded one file using
arecord -f S16_LE -c1 -r16000 goforward.raw
To trasncribe the audio, you can
]]>This closely follows but also includes the Pi dependencies:
sudo apt-get install swig oss-compat pulseaudio libpulse-dev automake autoconf libtool bison python-dev
For all benchmarks I recorded one file using
arecord -f S16_LE -c1 -r16000 goforward.raw
To trasncribe the audio, you can use
time pocketsphinx_continuous -fwdflat no -bestpath no -maxwpf 5 -maxhmmpf 10000 -topn 2 -pl_window 7 -infile goforward.raw
Intel(R) Core(TM) i5-4310U CPU @ 2.00GHz: ~1-2 second for 2 seconds audio
Raspberry Pi 2: ~7-8 seconds for 2 seconds audio
Transcribe Audio (limited dictionary)
Make a dictionary first. Generate a file language.txt with some words, like
open browser
new e-mail
forward
backward
next window
last window
open music player
okay computer
then go by uploading language.txt. Download the resulting tar and use tar -xvzf TAR*.tgz and then use the command:
time pocketsphinx_continuous -fwdflat no -bestpath no -maxwpf 5 -maxhmmpf 1000 -topn 2 -pl_window 7 -dict 4182.dic -lm 4182.lm -infile goforward.raw
Intel(R) Core(TM) i5-4310U CPU @ 2.00GHz: ~0.1 seconds
Raspberry Pi 2: ~1.4 seconds
Keyword search
pocketsphinx_continuous -kws phrases.kws -kws_threshold 1e-20 -infile goforward.raw
where phrases.kws has a couple of phrases to look for.
Intel(R) Core(TM) i5-4310U CPU @ 2.00GHz: ~0.25 seconds
Raspberry Pi 2: ~2.5 seconds
Download
git clone https://github.com/cmusphinx/sphinxbase.git
git clone https://github.com/cmusphinx/pocketsphinx
Configure and Install Pocketsphinx
cd sphinxbase
./autogen.sh
./configure
make && sudo make install
Add the following to ~/.profile:
export LD_LIBRARY_PATH=/usr/local/lib
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
then
source ~/.profile
cd ../
cd pocketsphinx
./autogen.sh
make && sudo make install
Boss makes a really cool Audio player with guitar effects, the JS-8. It turns out that some of the cool sounds that is has can be downloaded directly via a little hacking.

You'll need to create a fake JS-8 device. To do this you basically download the backup data and
]]>
Boss makes a really cool Audio player with guitar effects, the JS-8. It turns out that some of the cool sounds that is has can be downloaded directly via a little hacking.
You'll need to create a fake JS-8 device. To do this you basically download the backup data and then format a thumbdrive so that it looks like a JS-8 device.
- Insert a thumbdrive, format it and name it "JS-8".
- Unzip the "eBand JS-8 factory installed data in the included SD Card" and drag the "ROLAND" folder onto the newly formatted thumbdrive.
- Unzip, then install "eBand Song List Editor"
- Open "eBand Song List Editor", it will automatically detect your faked JS-8 device and allow you to export all the songs from it.
As many have already done, I ventured to make a retweet-to-win bot on Twitter to investigate how many of the contests are real.
So far 21,000 contests have been entered and 67 have been won, giving a winning percentage of 0.31%. When I enter a given contest it
]]>
As many have already done, I ventured to make a retweet-to-win bot on Twitter to investigate how many of the contests are real.
So far 21,000 contests have been entered and 67 have been won, giving a winning percentage of 0.31%. When I enter a given contest it an average of 41 retweets with a standard deviation of 104 retweets.
What kind of prizes can one expect?
An analysis of thousands of the entries revealed the following word cloud:

How many contests are actually real?
How many of the retweets are even real? Maybe not many of them. Suppose on average, a contest saturates at 40 retweets, giving me a 1/40 chance of winning. My winning percentage should be roughly equal to the 1/40, so given I won 67 contests there should have been ~3,000 contests that are definetly real. This is a very rough estimate.
However, I have actually entered 21,000 contests. Assuming the above, that means most of the contests are not real or have no intention of paying out.
Some physical contests recieved
- Limited South Park Monopoly (worth $150)
- Workaholics bobblehead
- $50 gift certificate to Amazon
- $20 gift certificate to Amazon
- DVD of the Vatican Tapes
- DVD of Key and Peele seasons 1+2
- PS4 game Madden 2015
Total revenue: $70 Total expenses: ??
Sample of contests won
-
Autographed cookbook\
Follow and retweet for a chance to win autographed cookbook (contest ends 8 am Aug 17)
— K-W Oktoberfest Inc. (@KW_Oktoberfest)Congratulations on winning the RT contest for a signed copy of 's cookbook.
— K-W Oktoberfest Inc. (@KW_Oktoberfest) -
Two passes to Indian Film Festival
is coming to Wyndham 30/8. We’re giving away 5 dble passes to the main festival 15-27 Aug Retweet to win
— Wyndham City Living (@WyndhamLiving) -
Mixing or mastering services
1PM: Retweet for a chance to win one of our mixing or mastering services! Winners announced at 10pm EST.
— Orso Audio (@orsoaudio)Monday Giveaway Winners - 12PM: 1PM: 2PM: 3PM: 4PM: 5PM:
— Orso Audio (@orsoaudio) -
5$ mGift card to Dunkin Donuts
RT for a chance to win a \$5 DD mGift!
— Dunkin' Donuts VT (@DunkinVermont) -
Black Ops3 Beta code
Rt for a chance to win a bo3 beta tomorrow at around 10 am uk time! 3 to give away
— mattymoffitt (@MATTY_MOFF) -
Tickets to see Irish film festival
See Tadhg O’Sullivan director of the upcoming The Great Wall discuss some of his new and older films RT to win!
— Irish Film Institute (@IFI_Dub) -
Fantasy novel
A great review, sequel to American Craftsman Also, RT to win a copy. See post for more details.
— BestFantasyBooks (@fantasy_books) -
Snacks
Congratulations, you’ve won our treats! Please could you send your address to [email protected]?
— BMF (@BritMilFit) -
Two tickets to dance performance
Follow & RT to win 2 x tix to the award winning Correction by today 20.15 Winner picked at random at 6.pm
— Budweiser Budvar (@BudvarUK) -
Four tickets to see George Clinton in San Diego
Do U like fun times? We like fun times! & R playing tonight - RT to win tix
— FM 94/9 (@FM949sd) -
Back Ops3 Beta code
RT for a chance to win Beta Codes!
Info:
— ASTRO Gaming (@ASTROGaming)
Stream: -
Two tickets to Men Without Hats in Dallas, Texas
We're sending you & your dancing partner to 8/23 at GMBG! RT to win!
— GasMonkeyDallas (@GasMonkeyDallas) -
Football digital card? 96 fairley
Giveaways for loyals retweet for a chance to win starts at 50 retweets
— Madden Ut\_11 (@Rjthegoat11) -
Sampler pack of tea
time! Follow and RT to a from ! 3 will be chosen on 8/22!
— TeaCat (@BlackCatBytes)CONGRATS to & for winning a sampler pack of tea! Please PM me your addresses! :)
— TeaCat (@BlackCatBytes) -
Tickets to homebuilding and renovation show in London
Retweet to win 1 of 5 pairs of tickets to the Homebuilding and Renovating Show @ ExCel London!
— Radflek (@Radflek) -
Tickets to movie preview in South Africa
If you live in or near - RT to win dbl tickets to watch Jenny's Wedding Thurs 8pm
— Bride&co (@BrideandcoSA) -
Everglow CD (a canadian band)
Show Review of & by RT for a chance to win autographed Everglow CD's!
— Canadian Beats (@CanadianBeats1)We have two winners of cd's, congratulations and Please DM me your addresses fr shipping!
— Canadian Beats (@CanadianBeats1) -
Two tickets to see a band in Long beach
! RT to win a FREE pair of tix to w/ & on 8/26!
— Federal Underground (@FedUnderground)Congrats on winning tix! Reply w/ full name, tix will be held in your name
— Federal Underground (@FedUnderground) -
Tickets to a 3D movie in Nairobi
Glad to see you tonight welcome to . Retweet for a chance to win a movie ticket to watch any 3D movie of your choice
— The Panari Hotel (@ThePanariHotel)congratulations you are our 2nd winner tonight please collect your ticket from the counter
— The Panari Hotel (@ThePanariHotel) -
Tickets to a fintess event in Chicago
buffs! We have 2 tix to tomorrow with and at McCormick. RT to win!
— Chiorganicgirls (@Chiorganicgirls) -
50$ gift certicate for Amazon!
It's at & all proceeds go to ! RT for a chance to win one of ten \$50 giftcards tomorrow AM.
— Eric Lundin (@TubePipeJournal) -
Megaman print
Friday AM just retweet for a chance to win 5"x5" glossy print! More prints coming soon.
— T.C.O.R (@TCOR1984)Winner \#2 DM us your address to mail you that print! Thanks man!
— T.C.O.R (@TCOR1984) -
Tickets to Latino summit in New York
Win Tickets to the Upstate Latino Summit! - Learn more: to win!
— IBERO (@IberoRochester) -
Free trial of a VPN service
RT for a chance to win a promo code for 30 days of the VPN Unlimited service. 5 random winners will get a code tmr.
— VPN Unlimited (@vpnunlimited) -
Fishing Bob fishing light
Correction... is the winner! Thanks for all the RT's and look for more coming soon! Congrats!
— Bob Light (@Fishingboblight) -
Graphic novel
20 COMIXOLOGY CODES!
for a chance to a FREE download of my graphic novel, THE CHAIR!
— Peter Simeti (@petersimeti)
-
Romance audio book
RT by 8-31 for chance to win a Audible copy of The Cindy Chronicles!
— Kelsey Osborne (@KelseyKelsem) -
Tickets to a Beerfest in Indiana
BuyOurBottles still has 4 Fri. and 2 Sat. evening . RT for a chance to win! Winners will be announced this afternoon. Cheers!
— BuyOurBottles.com (@BuyOurBottles) -
CD from Matt Steady of acoustic music
Congratulations to ! You've won the signed CD of "Blood is thicker than gold" DM incoming
— Matt Steady (@MattStoicSteady) -
Two tickets to Coalminers gig in London
CONGRATS to You've won a pair of tix to 2morro's Coalminers gig!
— Hideaway Live (@hideawaylive) -
Vancouver International Film Festival tickets
hi, you won the tickets for "The Hamsters". Could you please confirm your name and contact with us through DM?
— Reel West Magazine (@reelwestmag) -
Tickets to see Jane Doze in California
-
Tickets to see PJ Powers
Keen to see at tomorrow night? We've got 2 tickets up for grabs. RT to win.
— Western Cape Gov (@WesternCapeGov) -
Tickets to the Raleigh Home Show
We're giving away tickets to , happening Sept 11 - 13 at the Raleigh Convention Center! RT for a chance to win
— Cary Magazine (@carymagazine) -
Free meal at Mocka Lounge in Carfill
WIN A FREE MEAL
RT to win. 5 winners will be chosen at random across Facebook, Twitter & Instagram so get involved.
— ✧ Mocka Lounge ✧ (@MockaLounge) -
Tickets to BBC Classical music festival
RT for a chance to 2 tickets to the from
— Classical963FM (@classical963fm) -
Some stickers
RT to win a FREE Sprinkles the Mad Truffle Hamster sticker!
— Sugar Arcade (@SugarArcade) -
Minecraft skins
\~Custom Skin Giveaway!
~Rules:
- RT
- Follow
- Fav (Optional)
~Ends at 30 Retweets (Can we do it?)
- 1:10 Winner Ratio
~Good Luck!
— ItzJavaCraft (@ItzJavaCraft) -
Dermatology treatment
It's time for another giveaway! RT to win a Dermalogica microzone treatment!
— Massage Works (@massageworksfwb) -
Tickets to Faster Pussycat show
Hey guys we r giving 5 tickets to come see us at the Faster Pussycat show this Thursday at the Palladium. RT to win
— No Hugs (@NoHugsBand) -
Maids of Honor trilogy books
The third novel--MAID OF WONDER--is out today. (Huzzah, !) Retweet until 3:00 for a chance to win all 3 books!
— Christian Trimmer (@MisterTrimmer) -
A Quesopalooza poster
RT for a chance to win one of these limited edition Quesopalooza posters! (10 Random Winners)
— Moe'sSouthwestGrill (@Moes_HQ) -
Tickets to a TV show screening
! RT for a chance to win 2 tickets to TONIGHT's VIP screening of & a sneak peak of !
— VibeMagazine (@VibeMagazine) -
A book about banking
What are you creating? Comment & RT to WIN The Banker's Code! Learn tried & true methods of Building!
— MPactWealth (@MPactWealth) -
Two tickets to see John Mack Millan in Boone, NC
Retweet for a chance to win 2 tickets to the John Mark McMillan concert this Friday night in Boone NC.
— Jason English (@jason_english) -
Tickets to see a screening
Winner to be chosen at 4pm! Follow us & RT 2 tickets to see classic The Full Monty this Thursday 17th 7pm @ Q-Park Castlegate Sheffield
— Q-Park UK (@QPark_UK) -
Lifetime use of website
Follow us and RT for a chance to win lifetime access to
— CCNA Train (@ccnatrain) -
Tickets to music show
NEW CONTEST: Follow & retweet to win 2 tix to Cloak & Dagger on 9/18! Winner chosen 9/17. Sponsor: Gas Monkey Bar N' Grill.
— Daily Campus Deals (@DCDeals4SMU) -
Tickets to comedy show
RT to win one of three pairs of Tickets for this weekend. Three pairs to win!
— Comedyworks (@mtl_comedyworks) -
Tickets to afterparty from film fest
RT for a chance to win tickets to the premiere of + the AFTER PARTY in Halifax! TONIGHT!
— Elevation Pictures (@Elevation_Pics) -
Tickets to a fashion show party
We're celebrating London Fashion Week! Retweet to win yourself some free tickets for tomorrow evenings show and party!
— The Roof Gardens (@TheRoofGardens) -
Rugby ball
an official Rugby Ball. Simply RT & FOLLOW US for a chance to win
— Richmond Fanzone (@RichmondFanzone) -
Two tickets to Make Love not War fest
Starting a new week with more double tickets to the Make Love Not War Festival on Sept 24! RT to WIN tickets!! Good luck!
— 2OV.fm (@2OVfm) -
Tickets to music show
WIN: Ticket to the US Premiere of 's at ! Just RT to enter!
— Prequel Records (@PrequelRecords) -
Mini umbrella
tomorrow! How are you getting to work? to win a Travelchoice umbrella (winner announced 10am)
— Travelchoice (@pcctravelchoice) -
McDonalds prize pack
Our tasty NEW Chicken Burger is finally here, ! RT for a chance to WIN a McD prize pack.
— McDonald's (@McDTampaBay) -
Bass picks
to A Pack! LAST CHANCE! WINNER in 1 HOUR
— HappyCatz (@RagingSquirrels) -
Beer coozie
Keeping your beverage nice & cold! RT for a chance to Pickapeppa !
— Pickapeppa Sauce (@Pickapeppa) -
Tickets to a cycle show
Fancy brightening up your weekend, visit tomorrow RT for a chance to win tickets
— Salice UK (@SaliceUK) -
Free Minecraft server
Follow, favourite and retweet for a chance to win a Minecraft server hosting for one month!
— HENLEYbls (@HENLEYbls) -
Pickapeppa sauce swag
Congrats to ! You win FREE Pickapeppa which includes BEER KOOZIES! DM us for details!
— Pickapeppa Sauce (@Pickapeppa) -
Superglue
Super glue keeps your stuff super secure, just the way we like it. RT to win a fresh new bottle.
— LivSecure (@LivSecure) -
Vibrator
Only 4 days left to for a chance to Unity Couple's Vibe!
— EdenFantasys.com (@EdenFantasys) -
Madden 2015 for PS4
Who wants madden 15 for ps4 unopened free. It's last year's game but hey it's just collecting dust here and it's free. Rt to win it.
— Nerd Out (@Out2Nerd) -
Tickets to emerald coast party
Retweet for a chance to win 2 tickets to on 10/24 at ! Winner will be picked 10/16 @ 4 pm.
— Emerald Coast Mag (@EmeraldCoastMag) -
DVD of movie
RT for a chance to win a DVD copy of Vatican Tapes starring talented
— Style Habit (@HabitStyle) -
Comedy Central swag ($250 worth?)
RT for a chance to win swag! Listen to 's album :
— TheLaughButton.com (@thelaughbutton)